mysql, InnoDb의 index 인덱스
디스크 읽기 성능에 따른 인덱스의 중요성
- SSD는 HDD보다 성능 상 좋지만 여전히 디스크 I/O가 컴퓨터에서 가장 느린 부분이다. 디스크 I/O의 처리가 성능 튜닝에 있어서 여전히 중요하며 이는 인덱스 설정과 큰 관련을 가짐.
순차 I/O와 랜덤 I/O
- 순차 I/O의 경우 디스크 헤더의 위치 이동이 없이 한 번에 기록한다. SSD는 HDD보다 빠르지만 큰 차이를 가지지 않는다.
- 랜덤 I/O의 경우 SSD는 HDD와 달리 원판이 없어 아주 빠르게 읽을 수 있다. SDD는 HDD에 대비하여 성능 상 빠르다. 읽기 작업이 중요한 데이터베이스에게 SSD는 적합한 스토리지이다.
- 그럼에도 불구하고 SDD의 랜덤 I/O는 여전히 순차 I/O보다 느리다.
- 쿼리를 튜닝하여 랜덤 I/O를 순차 I/O로 변경할 수 있는 방법은 그다지 많지 않다.
- 랜덤 I/O의 처리 범위를 줄이는 것을 목표로 해야 한다. 꼭 필요로한 데이터만 읽도록 쿼리를 개선해야 한다.
- SSD에서는 RAID 컨트롤러와 캐시가 MySQL과 디스크 간 파일 동기화 작업을 순차 I/O로 효율적으로 처리하도록 변환시켜 준다. SSD의 성능이 아무리 좋더라도 RAID 컨트롤러의 역할이 중요하다.
인덱스와 풀 테이블의 읽기 방식의 차이
- 인덱스 레인지 스캔은 데이터를 읽을 때 주로 랜덤 I/O를 사용한다. 세컨더리 인덱스의 값인 프라이머리 키에 대해서 순서를 보장되지 않는다.
- 풀 테이블 스캔은 순차 I/O를 통해 데이터를 스캔한다.
- 그러므로 데이터 웨어하우스나 통계 작업에서는 인덱스보다 풀스캔을 사용하곤 한다.
인덱스란?
- DBMS의 인덱스는 프로그래밍 언어의 SortedList와 유사하다.
- SortedList는 항상 정렬된 상태를 유지한다.
- DBMS는 INSERT, UPDATE, DELETE에 대한 성능을 포기하는 대신, 인덱스를 통한 정렬을 보장하여 SELECT에 대한 빠른 성능을 선택했다.
- 결과적으로 인덱스는 저장 속도의 성능을 저하시키는 요인이다.
- 인덱스는 일반적으로 B-Tree, Hash 중 하나를 사용한다.
- B-Tree: 가장 일반적이고 성숙한 알고리즘. 칼럼의 값을 변경하지 않고 원래의 값을 이용하는 알고리즘. 일반적은 DBMS가 선택하는 알고리즘.
- Hash: 칼럼의 값을 해시로 계산하여 인덱싱하는 알고리즘. 전방 일치(like ‘str%’) 등 데이터의 일부나 범위를 통한 검색은 불가능. 대체로 메모리 기반의 데이터베이스에서 주로 사용.
B-Tree 인덱스
- B-Tree란 가장 먼저 도입되고 가장 범용적인 인덱스 알고리즘. 일반적인 용도에 적합.
- B-Tree의 B는 Binary가 아닌 Balanced이다.
구조 및 특성
- 루트 노드 - 브랜치 노드 - 리프 노드로 구성.
- 리프노드는 항상 실제 데이터 레코드를 찾아가기 위한 주솟값을 가지고 있음.
- 아래는 InnoDB 인덱스의 구조를 표현한 이미지이다. 인덱스 노드는 B-Tree로 정렬되어 있으나 실제 레코드의 주소는 정렬되어 있지 않아 랜덤 I/O가 발생한다.
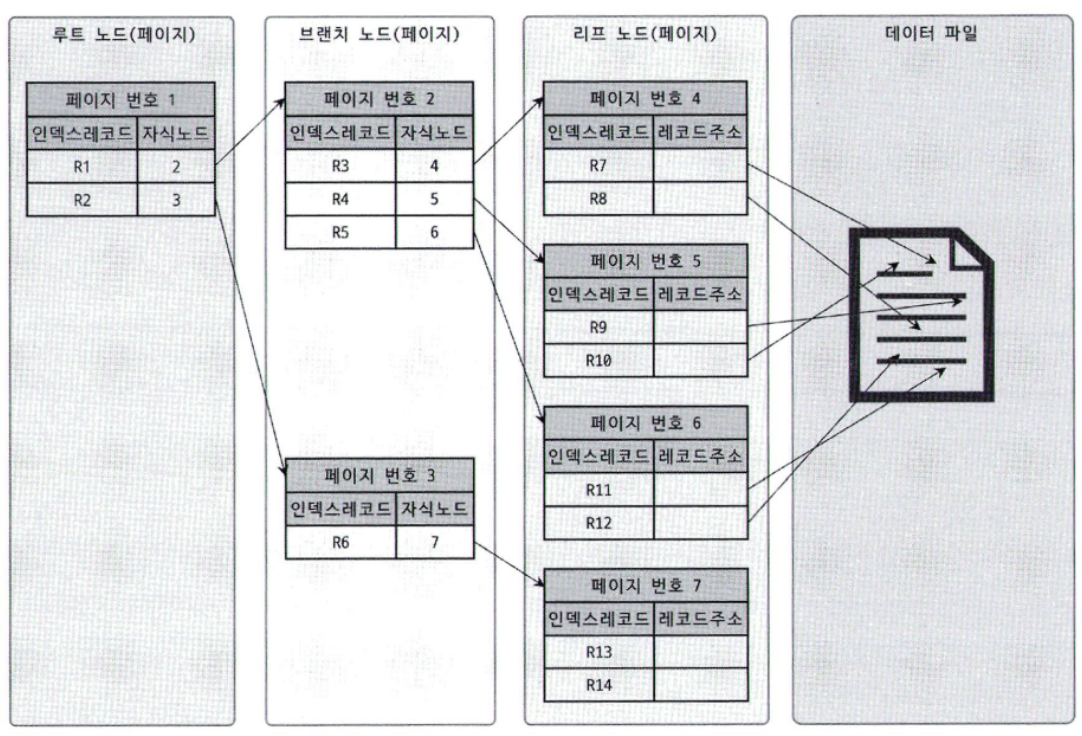
- 리프노드의 레코드의 주소는 MyISAM과 InnoDB가 다르다.
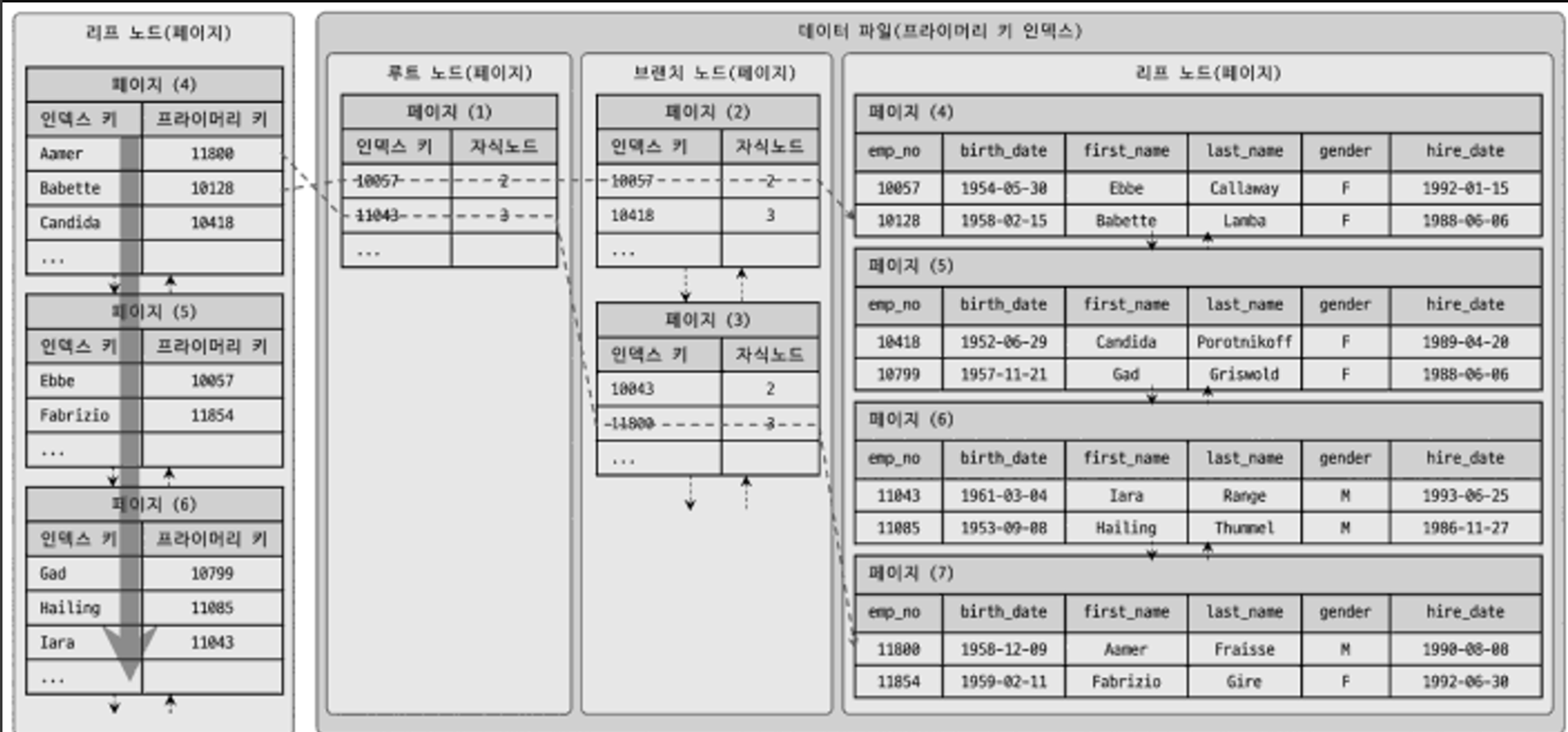
- MyISAM의 경우 실제 데이터 파일의 위치(ROWID)를 가리킨다.
- InnoDB 중 세컨더리 인덱스는 논리적인 주소로서 프라이머리 키를 가리킨다. 프라이머리 키는 다시 한 번 클러스터링 된 인덱스(B-tree)를 거쳐서 실제 물리 데이터에 접근한다.
B-Tree 인덱스 키 추가 및 삭제
인덱스 키 추가
- 인덱스 키를 추가할 경우, 1) 그 키가 있어야 할 노드를 찾아야 하며 2) 만약 해당 노드가 꽉 차있을 경우 노드를 분리해야 한다. 이로 인하여 쓰기 작업은 느리다.
- 인덱스 키 추가에 필요로한 작업 비용은 대체로 다음과 같이 본다.
- 레코드를 추가하는 작업 비용은 1일 경우,
- 인덱스에 키를 추가하는 작업은 1.5를 추가함.
- 만약 한 테이블에 인덱스가 3개 있을 경우, 1.5 * 3 + 1, 총 5.5배 비용을 더 사용한다.
- 다만, InnoDB는 체인지 버퍼 등 인덱스 변경을 지연하는 기능을 제공한다.
인덱스 키 삭제
- B-Tree에서 인덱스 키 삭제는 간단하다. 해당 키를 찾고 삭제 마크 한다.
인덱스 키 변경
- 인덱스의 키 값이 변경된다는 의미는 노드가 변경 되거나 같은 노드 내에 위치가 변경됨을 의미한다. 그러므로 기존 키를 삭제하고 새로운 키 값을 추가한다.
인덱스 키 검색
- B-Tree의 루트 노드부터 브랜치 노드, 리프 노드까지 비교 작업을 수행한다. 이를 트리 탐색이라 한다.
- INSERT, UPDATE, DELETE라 하더라도 먼저 해당 레코드의 위치를 찾아야 한다. 결과적으로 CRUD 작업 전체는 인덱스를 필요로 한다.
- 완전 일치, 값의 앞부분(Left-most part) 일치, 부등호 비교 등 사용 가능하다.
- 값의 뒷부분 일치, 함수 사용 등으로 인덱스 키 값으로 사용되는 칼럼 데이터가 변형된 경우 인덱스를 사용할 수 없다.
- 인덱스로 어떤 칼럼을 잠금과 함께 검색할 경우, 먼저 해당 인덱스를 잠근 후 테이블의 레코드를 잠근다. 이 과정에서 넥스트 키락 등 불필요하게 많은 레코드가 잠길 수 있다. 잠금이 발생할 경우 안정적인 처리를 위하여 적절한 인덱스 설계가 필요하다.
B-Tree 인덱스 사용에 영향을 미치는 요소
인덱스 키 값의 크기
- InnoDB는 데이터 저장의 가장 기본 단위를 페이지 또는 블록이라 한다. 인덱스 노드 역시 페이지를 기본 단위로 한다.
- 하나의 노드가 가질 수 있는 자식노드의 크기는 페이지 크기와 인덱스 크기에 의존한다.
- 페이지 노드가 기본 값으로 16kb이며
- 인덱스의 키가 16바이트이며 자식노드 주소가 12바이트일 경우
- 16*1024/(16+12)=585 개를 저장할 수 있다. 하나의 페이지에 585개의 자식노드를 가질 수 있다.
- 결과적으로 인덱스 키의 길이가 짧아지면 짧아질 수록 필요로 한 노드의 갯수가 줄어든다. 이 경우 디스크 읽기 횟수가 늘어나고 노드가 꽉 차서 노드가 분할하는 횟수가 늘어난다. 더불어 인덱스 전체 데이터 양이 늘어난다.
- 결론적으로 인덱스 키 값의 크기는 가능하다면 작게 한다.
B-Tree 깊이
- B-Tree의 깊이는 직접 조절할 방법이 없다.
- 인덱스 길이를 줄여 그 깊이가 깊지 않도록 유도한다.
선택도(기수성)
- 선택도(Selectivity) 또는 기수성(Cardinality)는 거의 같은 말이다. 모든 인덱스 키 값 가운데 유니크한 값의 수를 의미한다.
- 전체 인덱스 키 값은 1000개인데, 그 중 유니크한 값이 10개라면 기수성은 100이다.
- 대체로 기수성은 낮을 수록 좋다. 기수성이 작을수록 처리해야 하는 레코드의 갯수가 작아지기 때문이다.
- 디만 그룹핑이나 기타 필요에 따라 기수성이 높은 칼럼을 인덱스로 생성하는 것이 유리할 수 있다.
인덱스 사용의 비용이 더 클 때
- 일반적으로 옵티마이저는 인덱스를 통해 1건을 읽는 것을 테이블에서 직접 레코드 1건을 읽는 것보다 4-5배 정도 비용이 더 필요하다고 본다.
- 이 말은 인덱스를 사용하더라도 검색 레코드가 전체 레코드의 20-25%를 넘어갈 경우, 옵티마이저는 인덱스를 사용할 수 있더라도 테이블 풀 스캔을 선택할 가능성이 높다.
B-Tree 인덱스를 사용한 데이터 읽기 방식
인덱스 레인지 스캔
- 인덱스 레인지 스캔은 검색해야 할 인덱스의 범위가 결정됐을 때 사용하는 방식이다. 검색을 시작할 리프 노드를 선택하고, 필요로한 마지막 리프 노드에 닿을 때까지 순차적으로 인덱스를 읽는 방식이다.
- 인덱스 사용에 있어서 가장 빠른 방법이다.
- 인덱스가 정렬된 순서대로 리턴한 데이터가 정렬된다.
- 인덱스 레인지 스캔은 아래와 같은 순서로 동작한다.
- 인덱스에서 조건을 만족하는 값이 저장된 위치를 찾는다. 이 과정을 인덱스 탐색(index seek)이라고 한다.
- 탐색된 위치부터 필요한 만큼 인덱스를 순서대로 읽는다. 이 과정을 인덱스 스캔(index scan)이라 한다.
- 스캔으로 조회한 키와 주소를 이용하여 실제 레코드를 읽는다.
- 실제 데이터에 접근해야 할 경우 프라이머리키에 대한 랜덤 I/O가 발생하여 느릴 수 있다.
- 반대로 count와 같이 실제 데이터가 필요 없는 경우 해당 인덱스 테이블에서 작업을 완료하며 이 방식을 커버링 인덱스라 한다.
인덱스 풀스캔
- 인덱스 레인지와 다르게 인덱스를 처음부터 끝까지 모두 읽는 방식.
- 대표적으로 쿼리의 조건절에 사용된 칼럼이 어떤 인덱스에 존재하나 첫 번째 칼럼이 아닌 경우 사용된다. 테이블 풀 스캔으로 전체 데이터를 스캔하는 것보다 인덱스 테이블을 스캔하는 것이 비용이 덜 들기 때문이다.
- 다만, 인덱스 테이블로만 처리가능한 경우에만 동작한다. 만약 인덱스 테이블에 없는 칼럼 데이터를 요청한 경우 테이블 풀 스캔으로 처리한다.
루스 인덱스 스캔
- 듬성듬성하게 인덱스를 읽는 방식으로, 중간에 필요하지 않는 인덱스 키 값은 무시하고 다음으로 넘어가는 형태이다.
- group by에서 사용된다.
- 인덱스 index(a, b asc)가 생성되어 있고 쿼리가
select a, min(b) from tb group by a;일 경우, 인덱스 테이블에서 a칼럼의 새로운 값을 만날 때마다 첫 번째 레코드만 조회하면 된다.
인덱스 스킵 스캔
- 인덱스 스킵 스캔은 인덱스 칼럼 중 후행 열을 사용하는 쿼리에 최적화하는 방식이다.
- where에서 사용된다.
- 인덱스의 선두 열을 조회하지 않는 쿼리, 예를 들면
select a, b from tb where b > 10;같은 쿼리는 대체로 인덱스를 사용할 수 없다. 하지만 a의 카디널리티가 높을 경우 b는 정렬되어 있고 b > 10이란 범위를 순차적으로 처리할 수 있다. 즉, 동일한 a값을 가진 레코드 중에 b의 범위에 해당하는 부분만 스캔한다. - 따라서 a의 카디널리티가 클수록 스캔이 효과적이다.
- 커버링 인덱스가 가능해야 한다.
- 실행계획에 Using index for skip scan가 출력된다.
B-Tree 인덱스의 정렬
- 8.0 버전 이후 인덱스의 정렬 방식(오름차순, 내림차순)을 칼럼에 따라 정의할 수 있게 되었다.
- 인덱스의 검색 순서는 상황에 따라 위에서부터 아래로(정순), 아래서부터 위(역순)로 조회할 수 있다.
- index(col_a desc), index(col_b asc)
- MySQL은 다중 칼럼 인덱스을 지원하며 여러 개의 칼럼을 하나의 인덱스로 생성할 수 있다. 이 경우 두 번째 칼럼은 첫 번째 칼럼이 똑같은 레코드에 의존하여 정렬되어 있다.
- index(col_a asc, col_b desc)
- 다만 정순이 역순보다 빠르다. 양방향 연결 고리(double linked list)을 사용하지만 페이지 내부는 이미 정순을 기준으로 정렬되어 있기 때문이다.
B-Tree 인덱스를 효과적으로 사용하기 위한 기준
다중 칼럼 순서
SELECT * FROM dept_emp WHERE dept_no = 'd002' AND emp_no >= 10114 ;- 위 쿼리가 있고 이를 최적화하기 위에서는 dept_no와 emp_no 중 무엇을 먼저 인덱스 키로 선정해야 할까?
- index(dept_no, emp_no) : emp_no를 기준으로 레인지 스캔을 한 후 dept_no가 d002인 레코드를 선택한다.
- index(emp_no, dept_no) : emp_no가 d002인 범위 내에서 dept_no가 10114 이상인 값을 한 번에 추출한다.
- 결과적으로 인덱스 칼럼의 순서는 인덱스 성능에 중요한 영향을 미친다. 작업 범위로 최소화 하는 방식으로 인덱스를 설정해야 한다.
인덱스의 왼쪽 일치
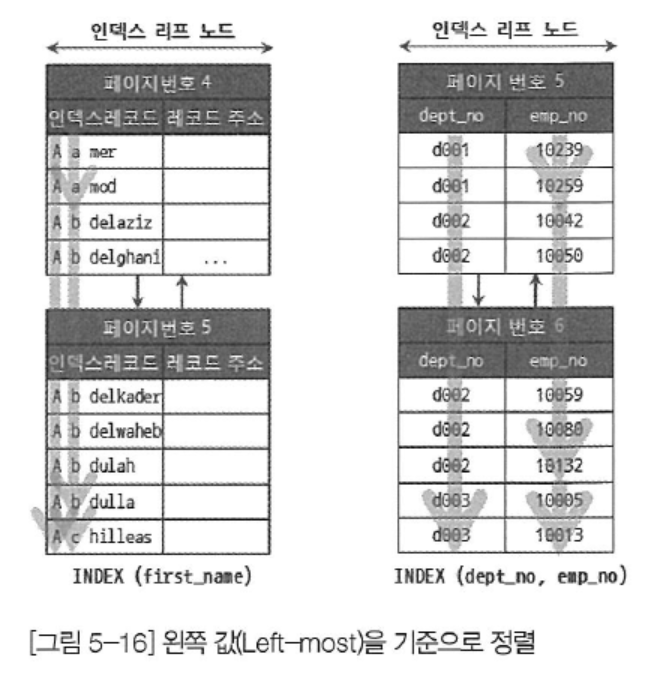
- 인덱스의 특징은 칼럼의 갯수와 상관 없이 왼쪽 값을 기준으로 정렬된다.
- 문자열칼럼의 경우 인덱스 키의 왼쪽부터 일치 여부를 확인한다.
- 인덱스가 여러 개일 경우 선행 칼럼을 먼저 검색한다.
- 결과적으로 왼쪽부터 처리하지 못하는 where 절은 인덱스를 효과적으로 사용할 수 없다.
그 외 기준
- 대체로 아래의 조건에서는 인덱스를 사용할 수 없다.
- NOT-EQUAL로 비교된 경우 (<>, NOT IN, NOT BETWEEN, IS NOT NULL)
where substring(indexed_col) = 'str'등 스토어드 함수나 다른 연산자로 인덱스 칼럼이 변형된 후 비교된 경우- SYSDATE() 등 NOT-DEERMINISTIC 속성의 스토어드 함수가 비교 조건으로 사용된 경우
- 데이터 타입이 서로 다른 비교 (인덱스 칼럼의 타입을 변환해야 비교가 가능한 경우)
- 문자열 데이터 타입의 콜레이션이 다른 경우
함수 기반 인덱스
- MySQL 8.0 이후 함수 기반 인덱스를 지원하기 시작했다. 일반적인 인덱스와 동일하나 인덱싱할 값을 계산하는 과정만 추가 되었다.
가상 칼럼을 이용한 인덱스
CREATE TABLE user (
user_id BIGINT,
first_name VARCHAR(10),
last_name VARCHAR(10),
PRIMARY KEY (user_id)
);
ALTER TABLE user
ADD full_name VARCHAR(30) AS (CONCAT(first_name, ' ', last_name)) VIRTUAL,
ADD INDEX ix_fullname(full_name);
EXPLAIN SELECT * FROM user WHERE full_name='Matt Lee';
함수를 이용한 인덱스
- 함수를 이용할 경우 아래와 같이 구조를 변경할 필요가 없다. 다만 그 표현식을 따라야만 한다.
CREATE TABLE user(
user_id BIGINT,
first_name VARCHAR(10),
last_name VARCHAR(10),
PRIMARY KEY (user_id),
INDEX ix_fullname ((CONCAT(first_name, ' ', last_name)))
);
EXPLAIN SELECT * FROM user WHERE CONCAT(first_name,' ',last_name)='Matt Lee';
멀티 밸류 인덱스
- 하나의 데이터 레코드가 여러 개의 키 값을 가질 수 있는 방식.
- 정규화에 위배되는 형태이지만, JSON 타입에 대응하여 지원.
- 다만, 이 경우 다음의 함수를 사용해야 함.
- MEMBER OF()
- JSON_CONTAINS()
- JSON_OVERLAPS()
CREATE TABLE user (
user_id BIGINT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(10),
last_name VARCHAR(10),
credit_info JSON,
INDEX mx_creditscores ( (CAST(credit_info->'$.credit_scores' AS UNSIGNED ARRAY)) )
);
INSERT INTO user VALUES (1, 'harris', 'lee', '{"credit_scores":[360, 353, 351]}');
SELECT * FROM user WHERE 360 MEMBER OF(credit_info->'$.credit_scores');
클러스터링 인덱스
- 클러스터링이란 여러 개를 하나로 묶는다는 의미. 클러스터링 인덱스란 프라이머리 키를 순서대로 묶어서 저장하는 방식. 유사한 데이터가 같이 있을 경우 조회 성능이 높아진다는 점에서 착안.
클러스터링 인덱스

- 클러스터링 인덱스는 프라이머리 키에만 적용.
- 클러스터링 과정이 실제 데이터를 저장하는 방법이 프라이머리 키에 의존하므로 신중하게 프라이머리 키를 결정해야 한다.
- 테이블 레코드의 저장 방식에 대한 방식으로서 클러스터링 인덱스보다 클러스터링 테이블이란 표현을 사용하기도 함.
- 클러스터링 인덱스(프라이머리 키)를 기준으로 검색하는 것이 가장 빠른 검색 방식.
- 클러스터링 인덱스의 리프 노드에는 레코드의 모든 칼럼이 같이 저장되어 있다.
- 어떤 레코드의 프라이머리 키가 변경(update)될 경우 해당 레코드의 리프 노드가 변경된다.
클러스터링 키의 선택
- InnoDB에서 다음과 같은 우선순위로 클러스터링 키를 선택한다.
- 프라이머리 키
- NOT NULL 옵션의 유니크 인덱스 중 첫 번째 인덱스
- 자동으로 유니크한 값을 가지도록 증가되는 칼럼을 내부적으로 추가하고, 추가한 칼럼
- 클러스터링 인덱스를 통한 혜택이 InnoDB에서는 매우 크다. 그러므로 반드시 프라이머리 키를 명시하여 클러스터링 인덱스를 사용하자.
클러스터링 장점과 단점
- 장점:
- 프라이머리 키의 검색 성능이 매우 빠름
- 커버링 인덱스를 사용할 수 있는 경우 효과적으로 처리 가능
- 단점:
- 클러스터링 인덱스를 위한 인덱스가 별도로 필요.
- 세컨더리 인덱스 -> 클러스터링 인덱스로 두 번 인덱스 사용.
- 레코드를 삽입할 때 프라이머리 키를 기준으로 정렬해야 함.
- 프라이머리 키를 변경 시 기존 레코드를 삭제하고 새롭게 삽입해야 함.
- 결과적으로 프라이머리 키에 대한 빠른 읽기가 장점이다. 단점은 프라이머리 키에 따른 느린 쓰기이다.
- 일반적인 OLTP에서 쓰기가 읽기에 대비하여 월등하게 크므로 대체로 클러스터링 인덱스가 유리하다.
클러스터링 테이블 사용 시 주의사항
클러스터링 인덱스 키의 크기
- 프라이머리 키가 길어질 경우 클러스터링 인덱스 및 세컨더리 인덱스의 크기가 커진다. 프라이머리 키는 가능하면 작게 한다.
프라이머리 키는 AUTO_INCREMENT보다는 업무적인 칼럼으로 생성(가능한 경우)
- 프라이머리 키의 검색은 매우 빠르다. 가능하면 자주 사용하는 칼럼을 프라이머리 키로 선택하는 것이 효과적이다.
프라이머리 키는 반드시 명시할 것
- 프라이머리 키를 정의하지 않으면 내부적으로 생성되어 접근 불가능하다. 그러므로 명시하여 프라이머리 키의 성능을 사용한다.
- ROW 기반 복제나 클러스터 등 다양한 환경에서 프라이머리 키가 없을 경우 성능 문제가 발생할 수 있다.
AUTO_INCREMENT 칼럼을 인조 식별자로 사용할 경우 주의사항
- 세컨더리 인덱스가 많이 필요하거나 프라이머리 키가 다중 칼럼 등으로 길어지는 경우 AUTO_INCREMENT로 사용하여 짧은 길이를 유지하는 것이 효과적일 수 있다.
- 만약 세컨더리 인덱스가 필요 없을 경우 다중 칼럼이라 하더라도 해당 조합을 프라이머리 키로 하는 것이 낫다.
- INSERT 위주의 칼럼은 정렬을 이유로 빠른 삽입을 보장하기 위해 AUTO_INCREMENT로 만들어진 인조 식별자가 성능 상 낫다.
유니크 인덱스
- 유니크는 제약조건이다. 하지만 MySQL에서 인덱스 없이 유니크 제약을 할 수 없다.
- NULL은 특정 값이 아니므로 2개 이상 저장될 수 있다.
유니크 인덱스와 일반 세컨더리 인덱스의 비교
인덱스 읽기
- 유니크 인덱스는 1건만 읽으면 되기 때문에 빠르다는 주장이 있으나 사실이 아니다. 레코드 1건에 0.1 초가 걸리고 2건에 0.2 초가 걸렸다고 하여 후자가 느린 것이 아니다.
- 결론적으로 인덱스 읽기는 유니크와 일반 인덱스와 차이가 미미하다.
인덱스 쓰기
- 유니크 인덱스는 키 값의 중복을 확인해야 한다.
- 중복된 값을 체크할 때 읽기 잠금을 사용하고, 쓸 때는 쓰기 잠금을 사용한다.
- 체인지 버퍼를 사용할 수 없다.
- 그러므로 쓰기의 경우 일반적인 상황보다 느리고 데드락이 발생할 수 있다.
- 결론적으로 꼭 필요한 경우가 아니라면 유니크 인덱스는 권장하지 않는다.
외래키 인덱스
- 외래키 제약이 설정되면 자동으로 연관되는 테이블의 칼럼에 인덱스가 생성된다.
- 외래키가 제거되지 않은 상태에서는 자동으로 생성된 인덱스를 삭제할 수 없다.
RealMySQL 8.0을 참고하여 작성하였습니다.