mysql, 쿼리 최적화 (select 쿼리 위주로)
들어가며
- 대체로 insert와 update 작업은 레코드 단위로 발생하므로 성능 상 문제가 크게 발생하지 않는다.
- select의 경우 여러 테이블을 조합하기 때문에 성능 상 문제가 발생할 경우가 많다.
- select 쿼리를 최적화하기 위한 방법을 정리한다.
- select 쿼리의 각 파트(select-from-where-…) 별로 구분하여 정리한다.
select 절의 처리 순서
- SELECT 문장은 다음과 같은 형태의 키워드와 절로 구성된다.
SELECT s.emp_no, COUNT(DISTINCT e.first_name) AS cnt
FROM salaries s
INNER JOIN employees e ON e.emp_no=s.emp_no
WHERE s.emp_no IN (100001, 100002)
GROUP BY s.emp_no
HAVING AVG(s.salary) > 1000
ORDER BY AVG(s.salary)
LIMIT 10;
- 특별한 조건이 없을 경우 대부분의 쿼리는 아래의 순서대로 처리된다.
- join & where: 드라이빙 테이블과 드리븐 테이블 간 합성
- group by
- distinct
- having
- order by
- limit
- 드라이빙 테이블에 대한 order by가 먼저 수행되기도 한다.
- where: 드라이빙 테이블에 대한 필터링
- order by
- join: 드리븐 테이블을 드라이빙 테이블에 조인
- limit
- 서브쿼리(인라인 뷰), with, 윈도우 함수 등 임시 테이블이 발생할 경우 위의 순서를 지키지 않을 수 있다. 다만, 결과적으로 임시 테이블에 대한 join을 수행한다고 가정한다면 위 순서와 차이를 가지지 않는다.
- with 절이나 윈도우 함수는 가장 먼저 실행되어 임시테이블을 생성한다.
where, group by, order by 절의 인덱스 사용
- 인덱스 사용에 있어서 where, group by, order by의 조건에 따라 사용되기도 하고 사용하지 못하기도 한다.
- 각 상황에 따라 어떻게 인덱스를 사용하는지 살펴보자.
인덱스를 사용하기 위한 기본 규칙
- 인덱스를 사용하기 위해서는 인덱스가 된 칼럼의 데이터를 변경해서는 안된다.
- 예를 들면 아래 where 절 중, 왼편은 인덱스를 사용하지 못하고 오른편은 인덱스를 사용한다.
where salary*10>1000->where salary>1000/10where string_value > 20000->where string_value > '20000'
WHERE 절의 인덱스 사용
- where절의 인덱스 사용은, 존재하는 인덱스의 칼럼에 대하여 적합하게 사용할 경우 특별한 제약사항이 없다.
- where절의 순서는 인덱스 사용에 있어서 중요하지 않다. 옵티마이저가 인덱스 순서에 따라 적절하게 where의 순서를 변경한다.
- OR가 있을 경우 풀 스캔을 하거나 인덱스 머지를 수행할 수 있으므로 주의해야 한다.
GROUP BY 절의 인덱스 사용
- group by의 경우 인덱스 사용이 제한적이다.
- 다중 칼럼 인덱스의 경우
- group by의 순서는 해당 인덱스의 순서와 같아야 하며 중간에 비어서는 안된다. 다만, 뒤의 칼럼이 생략할 수 있다.
- 해당 인덱스 이외에 다른 칼럼이 group by 절에 있어서는 안된다.
- 만약 다음과 같은 다중 칼럼 인덱스가 있을 경우, 아래와 같은 조건 이외에는 인덱스를 사용할 수 없다.
- (COL_1, COL_2, COL_3, COL_4)
- GROUP BY COL_1
- GROUP BY COL_1, COL_2
- GROUP BY COL_1, COL_2, COL_3
- GROUP BY COL_1, COL_2, COL_3, COL_4
- 다만, 다음과 같이 where 절을 만족할 경우 인덱스를 사용한다.
- WHERE COL_1= ‘상수’ … GROUP BY COL_2, COL_3, COL_4
- WHERE COL_1= ‘상수’ AND COL_2= ‘상수’ … GROUP BY COL_3, COL_4
- WHERE COL_1= ‘상수’ AND COL_2= ‘상수’ AND COL_3= ‘상수’ … GROUP BY COL_4
- 왜냐하면
WHERE COL_1= '상수' GROUP BY COL_2, COL_3, COL_4은WHERE COL_1= '상수' GROUP BY COL_1, COL_2, COL_3, COL_4과 동일하기 때문이다.
ORDER BY 절의 인덱스 사용
- group by와 거의 유사하다.
- 다만, 다중 칼럼 인덱스에서 설정한 오름차순(ASC)와 내림차순(DESC)이 정렬 조건에서 완전하게 일치하거나 완전하게 반전되어야만 인덱스가 동작한다.
- 예를 들면, (COL_1 ASC, COL_2 ASC, COL_3 ASC, COL_4 ASC) 인덱스 상태에서
ORDER BY COL_1, COL_2 DESC, COL_3로는 인덱스를 사용할 수 없다.
WHERE와 ORDER BY(또는 GROUP BY)를 함께 사용할 때 인덱스 사용
- where절과 order by를 함께 쓸 때 아래와 같은 형태로만 인덱스가 사용된다.
- where 절과 order by 절이 동시에 같은 인덱스를 이용
- where 절만 인덱스를 사용: file sort로 정렬해야 하므로 where 절의 조건에 일치하는 레코드가 적을 수록 좋다.
- order by 절만 인덱스를 사용: 아주 많은 레코드를 조회할 경우 주로 사용된다.
- order by가 다중 칼럼 인덱스의 칼럼 순서를 따르지 않더라도 아래와 같은 조건에서는 인덱스를 사용할 수도 있다.
where col_1 = '상수' order by col_2, col_3. 이는 앞서 group by와 같이 order by의 첫 칼럼에 col_1가 생략된 것과 같기 때문이다.
- 다만, 상수가 아닌 아래의 상황에서는
order by col_1, col_2, col_3처럼 인덱스 칼럼 전체를 명시해야 인덱스를 사용할 수 있다.where col_1 > '상수'와 같은 범위where col_1 in ('a', 'b', 'c')와 같은 값이 여러 개인 IN 절
GROUP BY 절과 ORDER BY 절의 인덱스 사용
- group by와 order by를 동시에 사용할 경우, group by 절과 order by 절의 칼럼이 동일하며 순서가 같아야 한다.
- 위 조건을 만족하지 않는 경우 인덱스를 사용하지 못한다.
WHERE 조건과 ORDER BY 절, GROUP BY 절의 인덱스 사용
- 세 개의 절을 동시에 사용할 경우 다음과 같은 순서대로 인덱스 사용 여부가 결정된다.
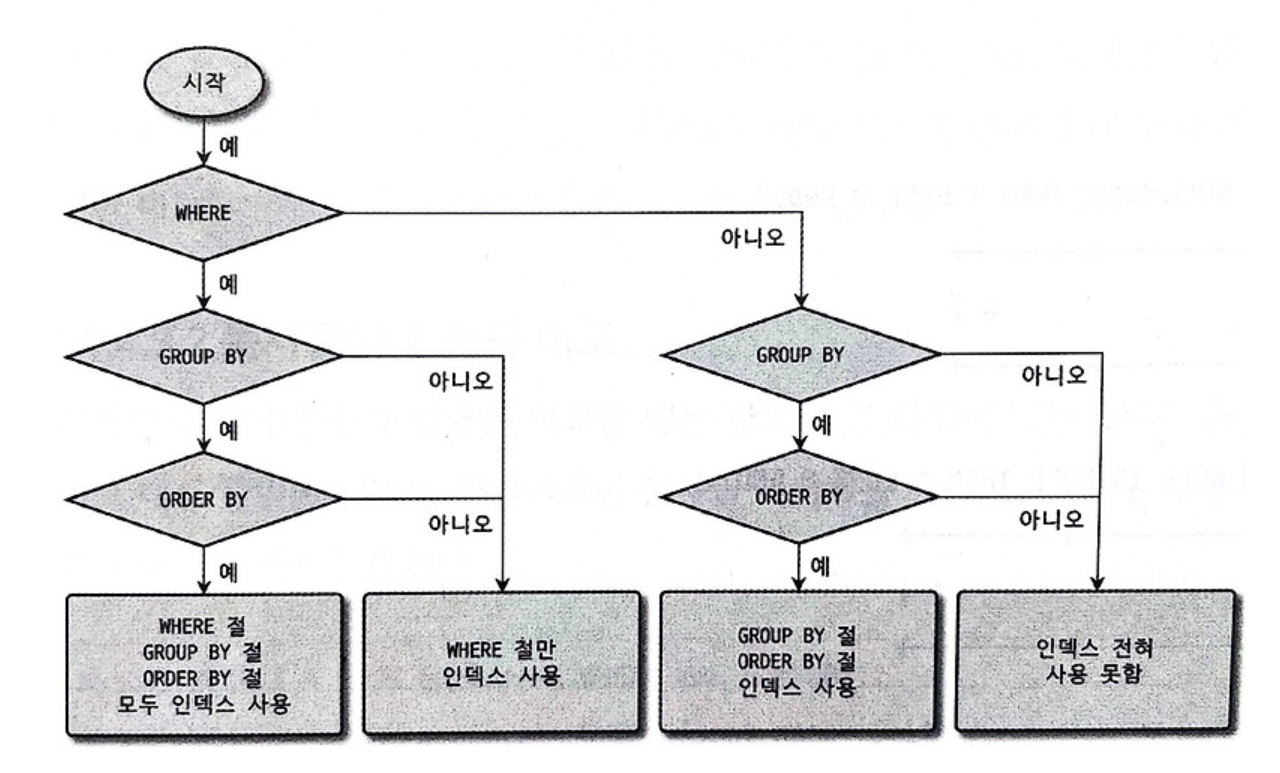
비교 연산 과정에서 주의 사항
NULL 비교
- MySQL은 NULL을 인덱스의 값으로 관리한다. 그러므로 NULL을 인덱스 검색 대상으로 사용할 수 있다.
- NULL을 비교할 수 있는 연산자는 아래와 같다.
- <=>
- IS NULL
- ISNULL()
문자열이나 숫자 비교
- 문자열 칼럼을 숫자 상수로 비교할 경우, 문자열 칼럼을 숫자 칼럼으로 변환한 후 비교한다. 인덱스를 사용할 수 없으며 동시에 풀스캔으로 인한 성능 문제가 발생한다.
- 그러므로 문자열 칼럼이나 숫자 칼럼을 비교할 때 그 타입에 맞는 리터럴 상수를 정확하게 사용하자.
날짜 비교
- MySQL에서의 날짜 타입은 대표적으로 DATE, DATETIME, TIME, TIMESTAMP이 있다.
- DATE와 DATETIME 칼럼과 문자열 상수로 비교할 때, 문자열이 날짜 타입으로 자동 변환된다. 이때 성능 문제가 존재하지 않으며 인덱스를 사용할 수 있다.
where date_col = '2023-01-01';
- 다만, datetime 칼럼을 date 상수와 비교할 경우, date 상수는 datetime으로 변환되는데 이때 시간은 00:00:00이 자동적으로 추가된다.
where datetime_col = '2023-01-01';의 리터럴은 다음과 같이 자동 변환:'2023-01-01 00:00:00';
- DATETIME과 TIMESTAMP 간 비교할 경우, TIMESTAMP는 단순한 숫자이므로 비교할 수 없다. 이 경우 timestamp를 datetime으로 변환해야 한다.
SELECT COUNT(*) FROM employees WHERE hire_date > '1986-01-01 00:00:00'; -- 264628
SELECT COUNT(*) FROM employees WHERE hire_date > UNIX_TIMESTAMP('1986-01-01 00:00:00'); -- 0, timestamp로는 비교 불가
SELECT COUNT(*) FROM employees WHERE hire_date > FROM_UNIXTIME(UNIX_TIMESTAMP('1986-01-01 00:00:00')); -- 264628
단축 평가(Short-Circuit Evaluation)
- 일반적인 개발 언어에서
if(false && fn())과 같은 코드가 있을 경우 첫 번째 조건인 false에 접근할 경우 두 번째 조건을 판정하지 않고 바로 다음 코드로 넘어간다. 이를 단축 평가라 하며 MySQL에서도 사용 가능하다. - MySQL에서 단축 평가는 다음의 절차에 따라 동작한다.
- where에서 인덱스가 있는 칼럼은 최우선으로 처리한다.
- 인덱스가 없는 칼럼의 경우 작성된 순서에 따라 위에서부터 아래로 순서대로 처리한다.
- 그러므로 인덱스가 없는 칼럼은 단축 평가를 고려하여 작성 순서를 결정해야 한다.
SELECT * FROM salaries WHERE to_date <'1985-01-01'; -- 인덱스가 없고 레코드의 갯수는 0이다.
SELECT * FROM salaries WHERE CONVERT_TZ(from_date, '+00:00', '+09:00')>'1991-01-01'; -- 인덱스가 없고 레코드의 갯수는 1개 이상이다.
- 만약 위와 같이 쿼리가 있을 경우 두 개의 조건절을 합성할 경우 어떻게 작성해야 할까?
SELECT * FROM salaries
-- WHERE CONVERT_TZ(from_date, '+00:00', '+09:00')>'1991-01-01' AND to_date <'1985-01-01'; -- 1번 쿼리
-- WHERE to_date <'1985-01-01' and CONVERT_TZ(from_date, '+00:00', '+09:00')>'1991-01-01'; -- 2번 쿼리
- 2번 쿼리를 선택해야 한다.
to_date <'1985-01-01'의 결과는 0개이므로 다음 비교를 할 필요가 없기 때문이다. 실제로 쿼리 속도는 2번 쿼리가 1번 쿼리보다 빠르다. - 이처럼 서브쿼리와 같이 복잡한 쿼리 역시 실행 시간이 오래 걸릴 것으로 예상되므로 뒤로 배치하는 것이 유리하다.
LIMIT
- LIMIT의 중요한 특성은 필요한 레코드 건수만 준비되면 즉시 쿼리를 종료한다는 것이다.
SELECT * FROM employees LIMIT 0,10;
SELECT * FROM employees GROUP BY first_name LIMIT 0, 10;
SELECT DISTINCT first_name FROM employees LIMIT 0, 10;
SELECT * FROM employees
WHERE emp_no BETWEEN 10001 AND 11000
ORDER BY first_name
LIMIT 0, 10 ;
- 첫 번째 쿼리: 테이블 풀 스캔을 수행하지만 10개의 레코드만 읽으면 멈추므로 매우 빠르다. LIMIT이 작업을 줄여 준다.
- 두 번재 쿼리: group by를 수행한 후 10개의 레코드를 읽어 느리다. LIMIT이 작업을 거의 줄이지 못한다.
- 세 번째 쿼리: first_name의 유니크 그룹만 찾으면 된다. 테이블 풀 스캔으로 유니크한 first_name을 가진 10개의 레코드만 찾으면 되므로, 상황에 따라 매우 빠를 수 있다. LIMIT이 작업량을 줄인다.
- 네 번째 쿼리: where 절에 일치하는 레코드를 읽은 후 first_name을 기준으로 정렬한다. 10개만 정렬하면 되므로 LIMIT의 작업을 줄여주지만 성능 상 유리한 쿼리는 아니다.
-
결과적으로 LIMIT 절이 있으면 어떤 의미로든 성능은 향상된다. 다만, 앞서 예제와 같이 ORDER BY, GROUP BY, DISTINCT을 적절하게 사용한다면 LIMIT을 활용할 때 작업량을 상당히 줄여준다.
- LIMIT을 사용할 때, 첫 번째 인자가 크면 클수록 검색 속도가 느려진다. 이런 경우 첫 번째 인자를 늘리는 것보다, where 절로 시작점을 찾고 조회하는 것이 낫다.
SELECT * FROM salaries
ORDER BY salary LIMIT 2000000, 10;
SELECT * FROM salaries
WHERE
salary>=38864
AND NOT (salary=38864 AND emp_no<=274049) -- 시작점 직전까지를 제외하기 위한 조건절
ORDER BY salary LIMIT 0, 10;
COUNT
- count(pk), count(1), count(*) 의 성능은 모두 같다.
- MyISAM은 메타 정보에 전체 레코드 건수를 관리하므로 count 함수의 성능이 매우 좋다.
- InnoDB의 경우 count를 위하여 모든 레코드를 조회한다. InnoDB를 사용할 때 count 함수 사용을 주의해야 한다.
- InnoDB에서 대략적인 갯수만 확인하는 경우 다음과 같이 메타 데이터를 통해 대략적으로 확인 가능하다. analyze를 수행할 경우 더 정확해진다.
-- 2844047
select count(1)
from salaries;
-- 299920
SELECT TABLE_SCHEMA, TABLE_NAME, TABLE_ROWS,
(DATA_LENGTH+INDEX_LENGTH)/1024/1024/1024 AS TABLE_SIZE_GB
FROM information_schema.TABLES
WHERE TABLE_SCHEMA = 'employees' AND TABLE_NAME='employees';
- count 쿼리를 할 때 굳이 필요 없는 쿼리(order by, left join)를 사용하여 성능 저하를 시키지 말자.
- count(column)을 할 경우 NULL 이 아닌 레코드의 갯수만 반환한다.
JOIN
JOIN의 순서와 인덱스
- 조인 작업에서 드라이빙 테이블을 읽을 때는 인덱스 탐색 작업을 단 한 번만 수행하고, 그 이후부터는 스캔만 실행하면 된다. 드리븐 테이블에서는 인덱스 탐색 작업과 스캔 작업을 드라이빙 테이블에서 읽는 레코드 건수 만큼 반복한다. 그러므로 옵티마이저는 드리븐 테이블을 최적으로 읽을 수 있게 실행 계획을 수립한다.
- 인덱스 간 조인이 발생한 경우 옵티마이저는 자동으로 최적화한다.
- 하나만 인덱스가 있을 경우 인덱스가 있는 테이블을 드리븐 테이블로 한다.
- 인덱스가 없는 테이블 간 조인을 수행할 경우 레코드 건수가 적은 테이블을 드라이빙 테이블로 선택한다. 드리븐 테이블의 풀스캔 횟수를 줄이기 때문이다.
JOIN 칼럼의 데이터 타입
- 조인은 칼럼 간 비교로 수행하므로 두 개의 타입이 일치해야만 인덱스를 효과적으로 사용할 수 있다. 대표적으로 다음의 조건에서 인덱스 사용이 제한된다.
- CHAR 타입과 INT 타입의 비교와 같이 데이터 타입의 종류가 완전히 다른 경우
- 같은 CHAR 타입이라더라도 문자 집합이나 콜레이션이 다른 경우
- 같은 INT 타입이더라도 부호(Sign)의 존재 여부가 다른 경우
OUTER JOIN의 성능과 주의사항
- MySQL 옵티마이저는 아우터 조인되는 테이블을 절대 드라이빙 테이블로 선택하지 못한다.
- 조인의 순서를 변경하여 가질 수 있는 최적화 기회를 잃지 않도록 가능하면 아우터 조인은 최소한으로 사용한다.
- 아래 예제는 아우터 조인의 예제이다. LEFT를 제거하여 이너 조인을 할 경우 유니크인
d.dept_name='Development'을 활용하지만, 아우터 조인은 어떤 상태가 되었든 e 테이블을 풀스캔한다.
explain
SELECT *
FROM employees e
LEFT JOIN dept_emp de ON de.emp_no=e.emp_no
LEFT JOIN departments d ON d.dept_no=de.dept_no AND d.dept_name='Development';
- 아래 세 개의 쿼리 중 첫 번째 아우터 조인과 두 번째 이너 조인의 실행 계획은 동일하다. 그 이유는 where 절에서 아우터 조인을 수행하는 테이블에 대해서 조회하기 때문이다. where 절을 수행할 경우 null은 제거되므로 사실상 이너 조인과 동일하기 때문이다. 옵티마이저는 이런 경우 자동으로 이너 조인으로 변환한다.
- 옵티마이저가 해당 쿼리를 아우터 조인으로 유지하도록 원한다면 세 번째 쿼리처럼 on 절에 해당 조건을 명시해야 한다.
SELECT *
FROM employees e
LEFT JOIN dept_manager mgr ON mgr.emp_no=e.emp_no
WHERE mgr.dept_no='d001 ';
SELECT *
FROM employees e
INNER JOIN dept_manager mgr ON mgr.emp_no=e.emp_no
WHERE mgr.dept_no='d001 ';
SELECT *
FROM employees e
LEFT JOIN dept_manager mgr ON mgr.emp_no=e.emp_no and mgr.dept_no='d001 ';
JOIN과 외래키
- 일반적인 생각과 달리 조인과 외래키 간 성능과 관련하여 아무런 연관이 없다. 인덱스의 유무가 중요하다.
지연된 조인(Delayed Join)
- 조인은 대체로 실행되면 될수록 레코드의 건수가 늘어난다. 그러므로 조인을 수행하기 전에 GROUP BY나 ORDER BY, LIMIT 등을 활용하여 최대한 레코드를 처리하고, 그 이후에 조인을 수행하는 것이 효과적이다. 이를 지연된 조인이라 한다.
- 아래 첫 번재 쿼리는 조인을 수행한 후 limit을 수행하였으며 두 번째 쿼리는 지연된 조인으로서 최대한 범위를 최소화 한 후 조인을 수행한다. 두 번째는 서브쿼리로 인한 임시 테이블을 사용하지만 조인 횟수가 적어 성능이 더 좋다.
SELECT e.*
FROM salaries s,
employees e
WHERE e.emp_no = s.emp_no
AND s.emp_no BETWEEN 10001 AND 13000
GROUP BY s.emp_no
ORDER BY SUM(s.salary) DESC
LIMIT 10;
SELECT e.*
FROM (SELECT s.emp_no
FROM salaries s
WHERE s.emp_no BETWEEN 10001 AND 13000
GROUP BY s.emp_no
ORDER BY SUM(s.salary) DESC
LIMIT 10) x,
employees e
WHERE e.emp_no = x.emp_no;
래터럴 조인(Lateral Join)
- 래터럴 조인은 외부 쿼리 FROM의 테이블의 칼럼을 참조할 수 있다.
- 래터럴 서브쿼리는 조인 순서상 후순위로 밀리고, 임시 테이블을 생성한다. 꼭 필요한 경우에 사용한다.
JOIN 결과를 정렬할 경우 명시적으로 ORDER BY를 사용
- 네스티드 루프 방식의 조인을 사용하는 경우 ORDER BY를 사용하지 않더라도 순서가 유지될 수 있다. 하지만 해시 조인으로 변경된 시점에서는 정렬되지 않는다.
- 암묵적인 정렬과 관계 없이 정렬이 필요하면 언제나 ORDER BY를 명시하자.
ORDER BY
- 어떤 DBMS도 ORDER BY를 명시하지 않은 경우 정렬을 보장하지 않는다. 그러므로 정렬이 필요한 경우 명시적으로 ORDER BY를 사용한다.
- ORDER BY를 사용할 때, 정렬을 위한 작업이 추가적으로 필요한 경우 실행계획에서는 “Using filesort”란 코멘트가 표시된다. 이 경우 반드시 디스크를 사용하는 것은 아니므로 경계할 필요는 없다.
SHOW STATUS LIKE 'Sort_%';를 통해 정렬 내역을 확인할 수 있다.
select col1, col2 from tb order by 2;의 형태로 작성 가능하다. 숫자 2는 두 번재 칼럼인 col2을 의미하며 col2를 기준으로 정렬한다. order by 절에서 숫자와 칼럼을 제외한 나머지는 무시한다.- ix_tb1_tb2(tb1 asc, tb2 desc)의 형태로 인덱스를 생성할 수 있으며, 칼럼마다 오름차순과 내림차순을 혼용할 수 있다.
서브쿼리
- 서브쿼리는 조인처럼 테이블이 섞이지 않아 가독성이 높고 복잡한 쿼리를 쉽게 작성할 수 있다.
- 서브쿼리에 대한 최적화가 MySQL 8.0 이후로 많이 이뤄졌다.
SELECT 절에 사용된 서브쿼리
- SELECT 절에 사용된 서브쿼리는 적절한 인덱스를 사용할 수 있다면 사용에 있어 주의사항은 크게 없다.
- 다만 서브쿼리보다 조인이 조금 더 빠르므로 가능하면 조인으로 쿼리를 작성한다.
- 제약 사항으로 하나 혹은 0개의 레코드를 리턴하는 스칼라 서브쿼리만 사용 가능하다.
select (select a from tb limit 1) as tb_a from ...;
FROM 절에 사용된 서브쿼리
- MySQL 5.7 이후부터 FROM 절의 서브쿼리와 외부 쿼리의 병합 성능이 많이 개선되었다.
- 다양한 조건에서 성능 최적화가 가능하나, 아래의 경우 불가능하다.
- 집합 함수 사용(SUM(), MIN(), MAX(), COUNT () 등)
- DISTINCT
- GROUP BY 또는 HAVING
- LIMIT
- UNION(UNION DISTINCT) 또는 UNION ALL
- SELECT 절에 서브쿼리가 사용된 경우
- 값이 변경되는 사용자 변수가 사용된 서브쿼리
WHERE 절에 사용된 서브쿼리
- 동등 또는 크다 작다 비교
= (select...)- MySQL 5.5버전부터 서브쿼리를 먼저 실행하여 상수로 변환한 후 나머지 쿼리를 처리하여 성능 최적화가 되었다.
- 다만,
where (col1, col2) = (select ....)형태의 튜플은 인덱스를 활용하지 못하고 풀 스캔을 실행한다. 튜플을 사용한 동등 비교는 주의해야 한다.
- IN 비교
IN (select ...)- MySQL 5.6 버전 이후로 세미 조인 최적화로 인해 성능이 좋아졌다. 다만, 세미 조인을 고려한 쿼리 작성이 필요하다.
- NOT IN 비교
NOT IN (select ....)- 안티 세미 조인의 경우 성능 최적화가 어렵다. 최대한 다른 조건으로 검색 범위를 축소한 후 NOT IN 조건을 사용하도록 유도한다.
CTE(Common Table Expression)
- CTE는 SQL 문장 내에서 한 번 이상 사용될 수 있다.
- 옵티마이저에 따라 임시 테이블에 CTE 쿼리 결과를 저장할 수도 있고 그렇지 않을 수도 있다. 다만, SQL 문장이 종료되면 생성된 CTE 임시 테이블은 자동으로 삭제된다.
- CTE는 다양한 위치에서 사용 가능하다 일반적으로 사용하는 SELECT 절 앞을 기준으로 작성한다.
비 재귀적 CTE
- ANSI 표준에 따라 작성한다.
WITH cte1 AS (SELECT * FROM departments)
SELECT * FROM cte1;
SELECT *
FROM (SELECT * FROM departments) cte1;
- 첫 번째 쿼리와 두 번째 쿼리는 사실상 동일하게 동작한다. 실행계획 또한 같으며 이때 임시테이블을 생성하지 않는다.
- CTE를 사용하는 경우, 대체로 위와 같은 쿼리보다는 CTE를 여러 차례 호출한다. 아래 예제는 동일한 쿼리를 여러 번 호출하는 것을 개선하고 CTE를 활용하여 한 번만 호출하는 예제이다. 실제로 첫 번째 쿼리는 두 개의 임시테이블을 생성하나 다음의 CTE 쿼리는 한 번만 생성하여 성능 상 낫다.
SELECT *
FROM employees e
INNER JOIN (SELECT emp_no, MIN(from_date) FROM salaries GROUP BY emp_no) t1
ON t1.emp_no = e.emp_no
INNER JOIN (SELECT emp_no, MIN(from_date) FROM salaries GROUP BY emp_no) t2
ON t2.emp_no = e.emp_no;
WITH cte1 AS (SELECT emp_no, MIN(from_date) FROM salaries GROUP BY emp_no)
SELECT *
FROM employees e
INNER JOIN cte1 t1 ON t1.emp_no = e.emp_no
INNER JOIN cte1 t2 ON t2.emp_no = e.emp_no;
- 더불어 CTE는 직전에 정의된 CTE를 참조할 수 있다.
with cte1 AS (select 'world' as hello),
cte2 AS (select concat(hello, ', mysql!') as hello2 from cte1 )
select * from cte2; -- world, mysql!
- 결론적으로 CTE는 기존 FROM 절에 대비하여 다음 3가지의 장점이 있다.
- CTE 임시 테이블은 재사용 가능하므로 FROM 절의 서브쿼리보다 효율적이다.
- CTE로 선언된 임시 테이블을 다른 CTE 쿼리에서 참조할 수 있다.
- CTE는 임시 테이블의 생성 부분과 사용 부분의 코드를 분리할 수 있으므로 가독성이 높다.
재귀적 CTE
- 재귀적 CTE는 두 개의 파트로 분리된다.
- 비재귀적 쿼리 파트: 초기 데이터와 데이터 타입, 임시 테이블 구조 등을 정의한다.
- 재귀적 쿼리 파트: 정의에 맞춰 데이터를 생성한다.
- 아래 select 1은 비재귀적 파트이며 union all 다음 절은 재귀적 파트이다.
WITH RECURSIVE cte (no) AS (
SELECT 1
UNION ALL
SELECT (no + 1) FROM cte WHERE no < 5)
SELECT *
FROM cte;
| no |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
- 재귀적 CTE가 데이터를 생산할 때 가장 마지막의 레코드를 참조한다.
- 위 예제에서 재귀적 쿼리 파트가 세 번째 실행될 때, 비재귀적 쿼리 파트에서 이미 실행된 값이 1인 레코드를 제외하고, 2와 3가 이미 생성되어 있을 것이다.
- 이때 3인 레코드를 참조하여 재귀적 쿼리 파트를 실행한다.
- 재귀적 CTE의 종료 조건은 where 절에 의존하는 것이 아니다. 재귀적 쿼리 파트의 결과로서 레코드가 0개가 될 때가 종료 조건이다.
- 마지막 실행 시점에서 재귀적 쿼리 파트는 마지막 레코드인 ‘select 5’를 참조할 것이다.
- select 5는
no < 5에 해당하지 않으므로 쿼리 결과 어떤 레코드를 생산하지 못하고 CTE는 종료된다.
- 데이터의 오류나 쿼리 작성자의 실수로 재귀적 CTE가 종료 조건을 만족하지 못하여 무한 반복할 수 있다. 이를 방지하기 위하여
cte_max_recursion_depth란 시스템 변수가 있다. 기본 값은 1000이다. - 이 값은 너무 크다. 글로벌로 낮은 값을 설정하고, 필요에 따라 힌트로 그 제한을 늘린다.
WITH RECURSIVE cte (no) AS (
SELECT 1 as no
UNION ALL
SELECT (no + 1) as no
FROM cte
WHERE no < 10000)
SELECT /*+ SET_VAR(cte_max_recursion_depth=10000) */ *
FROM cte;
윈도우 함수(Window Function)
- 집계 함수(group by)는 주어진 그룹을 하나의 레코드로 처리한다.
- 윈도우 함수는 조건에 일치하는 레코드 건수를 변경하지 않고 유지한 상태에서 집합 연산을 수행한다.
쿼리 각 절의 실행 순서
- 윈도우 함수는 where, from, group by, having 을 수행 한 후 처리된다. 그러므로 select, order by, limit은 윈도우 함수에 영향을 미치지 않는다.
SELECT emp_no, from_date, salary,
AVG(salary) OVER() AS avg_salary
FROM salaries
WHERE emp_no=10001
-- LIMIT 5;
-- LIMIT 10;
- 이에 따라 위의 쿼리 중 avg_salary의 결과는, select 된 5개의 평균이 아닌 emp_no=10001인 레코드 전체의 평균값이 된다.
- 그러므로 LIMIT에 어떤 값을 넣더라도 그 결과는 달라지지 않는다.
윈도우 함수 기본 사용법
- 윈도우 함수의 기본 사용법은 다음과 같다.
AGGREGATE_FUNC () OVER( <partition> <order> <frame>) AS window_func_column
SELECT de.dept_no, e.emp_no, e.first_name, e. hire_date
-- 동점은 같은 번호를 가지며, 동점의 갯수만큼 숫자를 누락하여 다음 번호 부여
, RANK () OVER(ORDER BY e.hire_date) AS rk1
, RANK () OVER(PARTITION BY de.dept_no ORDER BY e.hire_date) AS rk1_1
-- 동점은 같은 번호를 가지며, 연속된 번호를 보장
, DENSE_RANK () OVER(ORDER BY e.hire_date) AS rk2
-- 동점에 대한 고려 없이 연속된 번호를 부여
, ROW_NUMBER () OVER(ORDER BY e.hire_date) AS rk3
FROM employees e
INNER JOIN dept_emp de ON de.emp_no = e.emp_no
ORDER BY rk3 asc;
- over에서는 추가적인 연산을 위한 소그룹을 사용할 수 있으며 이때 frame으로 정의한다.
SELECT emp_no, from_date, salary,
-- 현재 레코드의 from_date를 기준으로 1년 전부터 지금까지 급여 중 최소 급여
MIN(salary) OVER(ORDER BY from_date RANGE INTERVAL 1 YEAR PRECEDING) AS min_1,
-- 현재 레코드의 from_date 를 기준으로 1 년 전부터 2 년 후까지의 급여 중 최대 급여
MAX(salary) OVER(ORDER BY from_date RANGE BETWEEN INTERVAL 1 YEAR PRECEDING AND INTERVAL 2 YEAR FOLLOWING) AS max_1,
-- from_date 칼럼으로 정렬 후, 첫 번째 레코드부터 현재 레코드까지의 평균
AVG(salary) OVER(ORDER BY from_date ROWS UNBOUNDED PRECEDING) AS avg_1,
-- from_date 칼럼으로 정렬 후, 현재 레코드를 기준으로 이전 건부터 이후 레코드까지의 급여 평균
AVG(salary) OVER(ORDER BY from_date ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS avg_2
FROM salaries
WHERE emp_no=10001;
- 프레임의 종류와 사용은 다음과 같다.
- ROWS: 레코드의 위치를 기준으로 프레임을 생성
- RANGE : ORDER BY 절에 명시된 칼럼을 기준으로 값의 범위로 프레임 생성
- 프레임의 시작과 끝은 다음과 같이 정의한다.
- CURRENT ROW: 현재 레코드
- UNBOUNDED PRECEDING: 파티션의 첫 번째 레코드
- UNBOUNDED FOLLOWING: 파티션의 마지막 레코드
- expr PRECEDING: 현재 레코드로부터 n 번째 이전 레코드
- expr FOLLOWING: 현재 레코드로부터 n 번째 이후 레코드
집계 함수와 비집계 함수
- 윈도우 함수는 집계 함수와 비집계 함수로 나뉜다.
- 집계 함수는
- GROUP BY 절과 함께 사용할 수 있으며,
- OVER() 없이 단독으로 사용 가능하다.
- 비집계 함수는 반드시 OVER() 절이 필요하다.
성능 문제
SELECT MAX(from_date) OVER (PARTITION BY emp_no) AS max_from_date
FROM salaries;
SELECT MAX(from_date) FROM salaries GROUP BY emp_no;
- 위 두 개의 쿼리는 결과가 다르므로 비교하기 어렵지만 성능과 관련한 평가를 할 수 있다.
- ix(emp_no, from_date) 인덱스가 존재한다.
- 두 번째 쿼리는 group by에서 인덱스를 활용하여 루즈 인덱스 스캔으로 유니크한 emp_no의 마지막 값(max)을 가져오면 된다.
- 첫 번째 쿼리는 모든 레코드의 갯수만큼 결과를 만들어야 하므로 인덱스 풀 스캔을 수행한다.
SELECT과 잠금
FOR UPDATE OF
- InnoDB는 잠금 없는 읽기(Non Locking Consistent Read)를 제공한다. 다만 필요에 따라 쓰기 잠금에는 FOR UPDATE, 읽기 잠금에는 FOR SHARE을 사용할 수 있다.
- 테이블 하나에만 영향을 미치면 좋을 텐데 조인을 사용하는 경우 조인에 사용한 모든 테이블에 락이 걸릴 수도 있다. 이를 방지하기 위하여 락을 걸기 위한 테이블을 한정할 수 있다.
SELECT *
FROM employees e
INNER JOIN dept_emp de ON de.emp_no=e.emp_no
INNER JOIN departments d ON d.dept_no=de.dept_no
-- FOR UPDATE; -- 모든 테이블에 락이 걸린다.
-- FOR UPDATE OF e; -- e에 대해서만 락이 걸린다.
NOWAIT, SKIP LOCKED
- MySQL 8.0 이전에는 잠금이 걸려 있을 경우, 해당 잠금이 해제될 때까지 기다려야 했다. 락이 계속 잠겨 있다면 innodb_lock_wait_timeout의 설정값에 따라 일정 시간을 대기한 후 에러 메시지를 받는다.
- MySQL 8.0 이후에는 락에 대응 가능한 다양한 기능을 제공한다.
NOWAIT
- 잠금을 획득하지 못하면 즉각 에러를 반환한다.
-- session1
SELECT CONNECTION_ID();
SELECT *
FROM salaries
WHERE emp_no = 10001
and salary = 60117 FOR UPDATE;
-- session2
SELECT CONNECTION_ID();
-- lock 발생
SELECT *
FROM salaries
WHERE emp_no = 10001
and salary = 60117 FOR UPDATE;
-- 에러 발생하고 바로 종료
-- [HY000][3572] Statement aborted because lock(s) could not be acquired immediately and NOWAIT is set.
SELECT *
FROM salaries
WHERE emp_no = 10001
and salary = 60117 FOR UPDATE NOWAIT;
SKIP LOCKED
- 요청한 레코드 중 잠금이 걸리지 않은 레코드만 가져 온다.
- 마치 QUEUE처럼 사용할 수 있으며 다음과 같은 쿼리로 사용할 수 있다. 이를 통해 높은 동시성을 확보할 수 있다.
-- session 1
SELECT CONNECTION_ID();
SELECT *
FROM salaries
WHERE emp_no = 10001;
-- 60117
SELECT *
FROM salaries
WHERE emp_no = 10001
LIMIT 1
FOR UPDATE SKIP LOCKED
;
-- session 2
SELECT CONNECTION_ID();
-- 60117. 락에 걸림
SELECT *
FROM salaries
WHERE emp_no = 10001
and salary = 60117
FOR UPDATE;
-- 60117 다음 레코드를 출력
SELECT *
FROM salaries
WHERE emp_no = 10001
LIMIT 1
FOR UPDATE SKIP LOCKED
;
- 확정적이지 않은(NOT-DETERMINISTIC) 쿼리로서 실행할 때마다 데이터의 불일치가 일어날 수 있다. STATEMENT를 기반으로 데이터베이스를 복제할 경우, SKIP LOCKED 쿼리는 데이터 불일치가 발생할 수 있다. 그러므로 복제는 ROW나 MIXED로 해야 한다.
INSERT
- 온라인 트랜잭션 상황에서 한 건 혹은 소량의 레코드에 대해서 INSERT를 수행하므로 성능에 고려할 부분이 많지 않다.
- 성능 보다는 구조 문제가 더 중요하다. SELECT과 INSERT 간 성능은 반비례 관계로 적절한 타협하여 적절한 테이블 구조를 선택해야 한다.
프라이머리 키 선정
- INSERT 성능에 가장 큰 영향을 미치는 부분은 프라이머리 키이다.
- 만약 INSERT 쿼리가 많을 경우
- 프라이머리 키는 단조 증가 혹은 단조 감수의 패턴이 유리하다.
- 세컨더리 인덱스가 적을 수록 더 빠르게 쓰기가 가능하다.
- 만약 SELECT 쿼리가 많을 경우
- 프라이머리키가 단조 증가 혹은 감소로 인한 삽입 성능 보다 프라이머리 키를 조회 대상으로 관리하는 것이 나을 수 있다.
- 세컨더리 인덱스가 많더라도 성능 상 큰 문제가 없을 수 있다.
- (책에서는) 백만개 수준의 테이블은 튜닝에 크게 고민하지 않자고 하는데…
Auto-Increment 칼럼
- 자동 증가(Auto-Increment) 칼럼은 MySQL에서 가장 빠른 INSERT를 보장하는 방식이다.
- 자동 증가 값에 대한 채번을 위해 잠금이 필요하며 이를 AUTO-INC 잠금이라 한다.
- AUTO-INC는 innodb_autoinc_lock_mode 변수로 설정한다.
- 0: 한 번에 1씩 가져온다.
- 1: 뮤텍스로 락을 사용한다. 락 성능이 좋으며 여러 레코드를 INSERT 할 경우 한 번에 채번한다.
- 2: AUTO-INC 잠금을 사용하지 않는다. 자동 증가 값을 적당량 할당 받아 처리한다. 엄격하게 단조 증가하지 않는다. statement 복제에서 사용할 경우 프라이머리 키가 달라질 수 있으므로 사용해선 안된다.
-
8.0 이후부터 기본값은 2이다. 반드시 연속한 값일 필요가 없으므로 가능하면 2를 사용한다.
SELECT LAST_INSERT_ID();- 현재 커넥션에서 가장 마지막에 증가된 AUTO_INCREMENT 값을 조회하는 함수.
LOAD DATA
- 일반적인 RDBMS에서 데이터를 빠르게 적재하는 방법으로 LOAD DATA를 사용한다. 스토리지 엔진의 호출 횟수를 최소화하고 엔진에 직접 데이터를 적재하므로 INSERT에 대비하여 매우 빠르다.
- 다만 단일 스레드, 단일 트랜잭션으로 실행하는 단점이 있다. 만약 시간이 길어질 경우 온라인 트랜잭션 쿼리의 성능에 영향을 받을 수 있다. 해당 작업(트랜잭션)이 끝나기 전까지 UNDO 로그를 유지해야 한다.
- LOAD DATA의 경우 여러 개의 파일로 준비하여 처리하거나, INSERT … SELECT … 문장으로 부분적으로 잘라 적절하게 처리하는 것이 낫다.
- 프라이머리키를 명시적으로 삽입할 경우, 프라이머리키를 기준으로 정렬한 파일은 그렇지 않은 것보다 훨씬 빠르게 삽입한다.
- 일반적인 INSERT와 마찬가지로 세컨더리 인덱스가 많을 경우 성능 상 문제가 발생할 수 있다.
UPDATE와 DELETE
UPDATE … ORDER BY … LIMIT n
- update와 delete 문장에서 order by와 limit 절을 사용하여 상위 몇 건만 변경 및 삭제할 수 있다.
- 한 번에 너무 많은 레코드를 변경 및 삭제할 때 과부화가 유발 될 것으로 예상할 때 사용 가능하다.
DELETE FROM employees ORDER BY last_name LIMIT 10;
JOIN UPDATE
- JOIN UPDATE를 사용하여 두 개 이상의 테이블을 조인한 후, 그 결과를 변경 및 삭제할 수 있다.
- 읽기 참조만 하는 테이블은 읽기 잠금이 걸리고, 변경하는 테이블은 쓰기 잠금이 걸린다. 그러므로 온라인 트랜잭션에서는 사용을 자제한다.
UPDATE tb_test1 t1, employees e
SET t1.first_name=e.first_name
WHERE e.emp_no=t1.emp_no
JOIN DELETE
- 테이블을 조인한 후, 조인에 성공한 레코드를 제거한다. 이때 DELETE의 alias 테이블에 대해서 삭제한다.
DELETE e, de, d
FROM employees e, dept_emp de, departments d
WHERE e.emp_no = de.emp_no
AND de.dept_no = d.dept_no
AND d.dept_no = 'd001 ';
쿼리 성능 테스트
- MySQL 서버는 운영체제의 파일 시스템 관련 기능을 이용하여 데이터 파일을 읽는다. 그러므로 운영체제의 영향을 받는다. 특히, MyISAM의 경우 운영체제가 관리하는 캐시나 버퍼를 활용한다. 이로 인하여 운영체제의 성능에 MySQL 서버의 성능이 좌우된다.
- InnoDB는 파일 시스템의 캐시나 버퍼를 사용하지 않는 Direct I/O를 사용하므로 운영체제의 영향을 덜 받는다. 더불어 MySQL 서버 내부의 자체 버퍼와 캐시를 사용한다. 그러므로 InnoDB의 쿼리 성능을 확인하거나 혹은 재시작 후 성능을 확보하기 위해서는, 캐시나 버퍼를 적절하게 사용하도록 워밍업을 해야 한다.
RealMySQL 8.0, 11장을 참고하여 작성하였습니다.